【中】分库分表带来的一些问题
在 十亿数据的订单分表 里面,已经搭建了一个分库分表的项目,它可以很好的运行,看起来也很简单(只需要在application里面加入一些配置即可)
但事情肯定不会如此简单,这次再来看看分库分表带来的一些问题,以及如何去解决
一、通用问题
- 连表的问题
- 事务问题
- 分页、排序问题
- 数据倾斜问题
- 非分片键查询的问题
- 复杂查询的问题(扩展到ES)
二、场景问题
2-1、场景描述
还是基于一个现实的场景,通过解决场景来回答问题
场景描述
实现一个待办任务系统,对任务系统实现增删改查。和普通任务系统不同的是,现在的这个任务系统有一个循环的功能,比如某个任务需要完成三次(比如周一和周三的晚上需要运动),我们希望这是一个任务需要执行两次。还有一个权限控制(为了增加连表的查询复杂度)
假设任务数据增长很快(一年千万级别的增长),用户只需要关注 T-1、T、T+1 年的数据
CREATE TABLE `t_xdx_plan` (
`id` bigint NOT NULL COMMENT 'ID(雪花算法)',
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '标题',
`recurrence_flag` int NOT NULL DEFAULT '0' COMMENT '是否循环 0=否 1=是',
`customer_id` int NOT NULL COMMENT '客户ID',
`modified` datetime NOT NULL,
`created` datetime NOT NULL COMMENT '创建时间(分表键)',
PRIMARY KEY (`id`),
KEY `idx_customer_id` (`customer_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='计划表';CREATE TABLE `t_xdx_plan_task` (
`id` bigint NOT NULL COMMENT 'ID(雪花算法)',
`plan_time` datetime NOT NULL COMMENT '计划行动时间',
`plan_month` varchar(7) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '计划月份 yyyy-MM',
`status` int NOT NULL COMMENT '状态 1=未完成 2=已完成 99=已失效',
`plan_id` bigint NOT NULL COMMENT '关联计划ID',
`modified` datetime NOT NULL,
`created` datetime NOT NULL COMMENT '创建时间(分表键)',
PRIMARY KEY (`id`),
KEY `idx_plan_id` (`plan_id`),
KEY `idx_plan_time` (`plan_time`),
KEY `idx_plan_month` (`plan_month`),
KEY `idx_status` (`status`),
KEY `idx_created` (`created`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='计划任务表';CREATE TABLE `t_xdx_plan_access_control_list` (
`id` bigint NOT NULL COMMENT 'ID(雪花算法)',
`plan_id` bigint NOT NULL COMMENT '计划ID',
`app_user_id` int NOT NULL COMMENT '线上用户ID',
`created` datetime NOT NULL COMMENT '创建时间(分表键)',
PRIMARY KEY (`id`),
KEY `idx_plan_id` (`plan_id`),
KEY `idx_app_user_id` (`app_user_id`),
KEY `idx_created` (`created`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='计划访问控制表';- t_xdx_plan > t_xdx_plan_task 是 1对N
- t_xdx_plan > t_xdx_plan_access_control_list 是 1对1
2-2、场景分析
基于上述,分表的规则肯定是基于年了。这里为了简化不必要的逻辑,假定T=2026,T-1=2025,T+1=2027。数据的插入,是基于时间来的
- t_xdx_plan 和 t_xdx_plan_access_control_list 是基于 created 时间
- t_xdx_plan_task 是基于 plan_time
也就是,当插入一次计划的时候,比如创建时间是 2026,可能会往以下表插入数据
- t_xdx_plan_2026
- t_xdx_plan_access_control_list_2026
- t_xdx_plan_task_2026、t_xdx_plan_task_2027
这便是最复杂的一个场景了,增删改查都会设计到多表的处理,且存在表在不同的年份上
三、代码开发
3-1、核心 shardingsphere配置
最重要的配置部分
表配置
# 计划主表
t_xdx_plan:
actual-data-nodes: ds_health.t_xdx_plan_$->{2025..2027}
table-strategy:
standard:
sharding-column: created
sharding-algorithm-name: health-plan-year-algorithm
# 计划任务表
t_xdx_plan_task:
actual-data-nodes: ds_health.t_xdx_plan_task_$->{2025..2027}
table-strategy:
standard:
sharding-column: plan_time
sharding-algorithm-name: health-plan-task-year-algorithm
# 计划访问控制表
t_xdx_plan_access_control_list:
actual-data-nodes: ds_health.t_xdx_plan_access_control_list_$->{2025..2027}
table-strategy:
standard:
sharding-column: created
sharding-algorithm-name: health-plan-acl-year-algorithm路由规则配置
# 健康计划主表分表算法:按 created 年份路由
health-plan-year-algorithm:
type: INTERVAL
props:
datetime-pattern: "yyyy-MM-dd HH:mm:ss"
datetime-lower: "2025-01-01 00:00:00"
datetime-upper: "2027-12-31 23:59:59"
# 取到数据后按照这个格式拼接到表后面:t_xdx_plan_ > t_xdx_plan_2026
sharding-suffix-pattern: "yyyy"
datetime-interval-amount: 1
datetime-interval-unit: "YEARS"
# 健康计划任务表分表算法:按 plan_time 年份路由
health-plan-task-year-algorithm:
type: INTERVAL
props:
datetime-pattern: "yyyy-MM-dd HH:mm:ss"
datetime-lower: "2025-01-01 00:00:00"
datetime-upper: "2027-12-31 23:59:59"
sharding-suffix-pattern: "yyyy"
datetime-interval-amount: 1
datetime-interval-unit: "YEARS"
# 健康计划ACL表分表算法:按 created 年份路由
health-plan-acl-year-algorithm:
type: INTERVAL
props:
datetime-pattern: "yyyy-MM-dd HH:mm:ss"
datetime-lower: "2025-01-01 00:00:00"
datetime-upper: "2027-12-31 23:59:59"
sharding-suffix-pattern: "yyyy"
datetime-interval-amount: 1
datetime-interval-unit: "YEARS"表绑定关系
# 健康计划:仅将 plan 与 acl 绑定(同按 created 分片,业务上同岁,不会出现 plan_2025+acl_2026)。
# task 不绑定,以支持 plan_2025 + task_2026 等跨年场景。路由数 = plan年×task年 = 3×3 = 9(若三张都绑定会漏数据,都不绑定则 3×3×3=27)。
binding-tables:
- t_order,t_order_item
- t_xdx_plan,t_xdx_plan_access_control_list3-2、增 (重要)
3-2-1、Java代码
/**
* 新增计划任务
* POST /api/plan/insert
*/
@PostMapping("/insert")
public Result<Long> insertPlan(@RequestBody PlanTaskInsert param) {
Long id = planService.insertPlan(param);
return Result.success(id);
}@Data
public class PlanTaskInsert implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 计划行动时间
*/
private LocalDateTime planTime;
/**
* 计划月份,格式:yyyy-MM
*/
private String planMonth;
/**
* 状态 1=未完成 2=已完成 99=已失效
*/
private Integer status;
/**
* 关联计划ID
*/
private Long planId;
/**
* 计划标题
*/
private String title;
/**
* 是否循环 0=否 1=是
*/
private Integer recurrenceFlag;
/**
* 客户ID
*/
private Integer customerId;
/**
* ACL 关联的线上用户ID
*/
private Integer appUserId;
}- createPlan 和 createAclIfNeeded 都是单个查询
- createPlanTask 里面会生成(写死的规则生成多个)多个,然后批量插入
- 数据源是一致的,所以事务还是用 @Transactional(rollbackFor = Exception.class)
@Override
@Transactional(rollbackFor = Exception.class)
public Long insertPlan(PlanTaskInsert param) {
log.info("新增计划任务, param: {}", param);
LocalDateTime now = LocalDateTime.now();
// 1. 插入 plan
Long planId = createPlan(param, now);
// 2. 插入 task(s)
createPlanTask(param, planId, now);
// 3. 插入 acl
createAclIfNeeded(param, planId, now);
return planId;
}shardingsphere 都是通过代理去增强SQL,所以原始SQL看起来还是单表的操作
<insert id="insert" parameterType="com.xdx.order.entity.XdxPlan">
INSERT INTO t_xdx_plan (id,title,recurrence_flag,customer_id,modified,created) VALUES (
#{plan.id},#{plan.title},#{plan.recurrenceFlag},#{plan.customerId},#{plan.modified},#{plan.created})
</insert><!-- 批量插入计划任务(逻辑表名,分片由 plan_time 路由) -->
<insert id="batchInsert" parameterType="java.util.List">
INSERT INTO t_xdx_plan_task (id,plan_time,plan_month,status,plan_id,modified,created) VALUES
<foreach collection="tasks" item="task" separator=",">
( #{task.id}, #{task.planTime}, #{task.planMonth}, #{task.status}, #{task.planId}, #{task.modified}, #{task.created} )
</foreach>
</insert><insert id="insert" parameterType="com.xdx.order.entity.XdxPlanAccessControl">
INSERT INTO t_xdx_plan_access_control_list (id, plan_id, app_user_id, created
) VALUES ( #{acl.id}, #{acl.planId}, #{acl.appUserId}, #{acl.created} )
</insert>3-2-2、分析
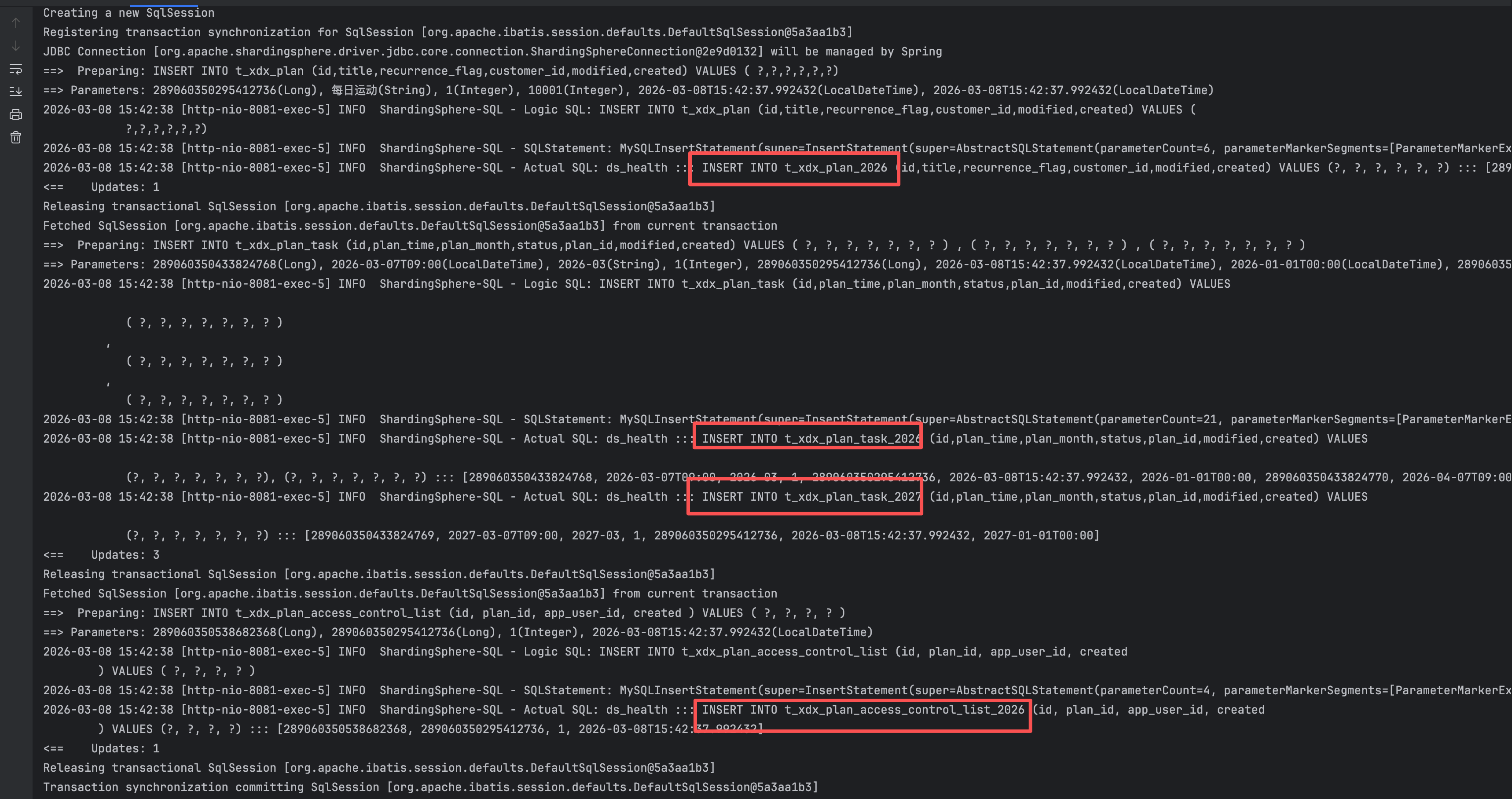
- t_xdx_plan、t_xdx_plan_access_control_list 表都是基于 created 来分表的, created 的年是固定的一个,所以对于 这两个表的插入,会直接找到对应的年份
- 在伪代码里面每次都会生成 T、T+1的task,所以对于 t_xdx_plan_task 表,会生成2个insert语句
- 一次插入,会insert 4次
对于t_xdx_plan_task 的表,有两种操作,一个是在代码里面,基于 planTime进行分组,然后多次batchInsert,也可以直接 batchInsert这样拆分操作就交给 shardingsphere
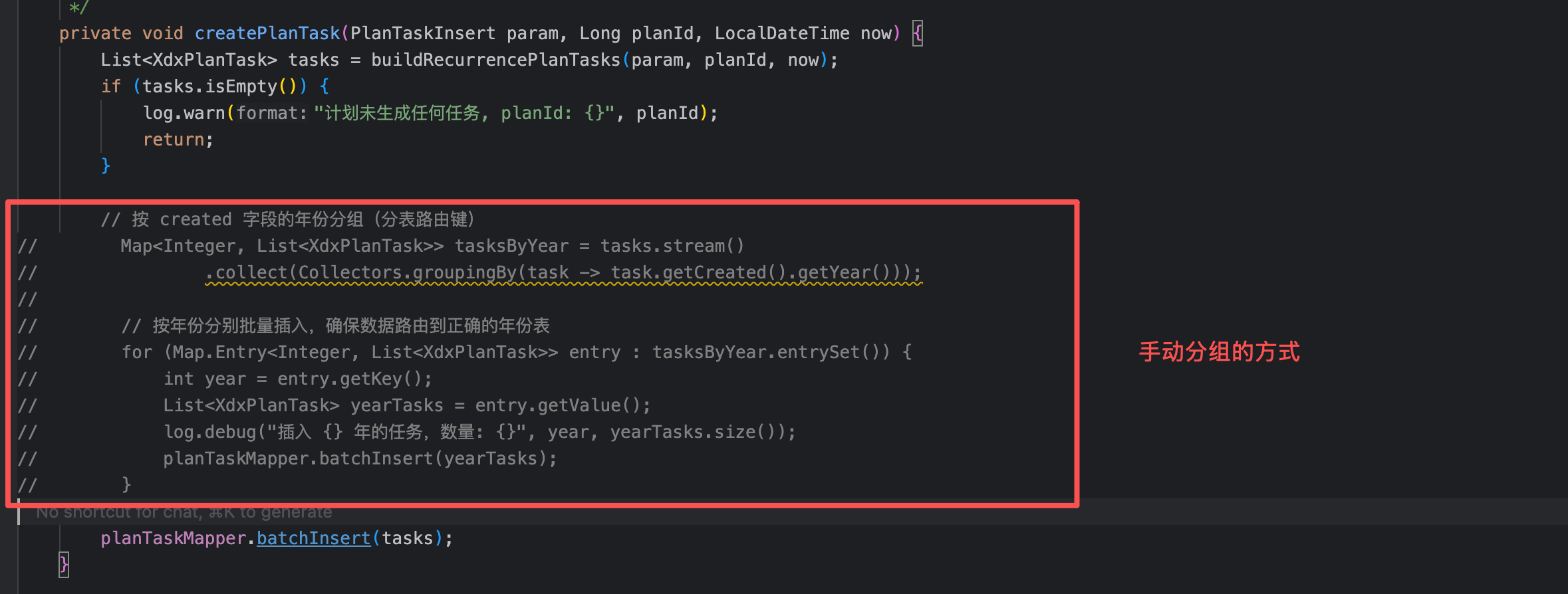
3-3、删
3-3-1、Java代码
@PostMapping("/delete")
public Result<Integer> deleteByPlanId(@RequestBody PlanDelete param) {
int rows = planService.deleteByPlanId(param.getPlanId());
return Result.success(rows);
}@Data
public class PlanDelete implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 要删除的计划ID
*/
private Long planId;
}@Override
@Transactional(rollbackFor = Exception.class)
public int deleteByPlanId(Long planId) {
if (planId == null) {
log.warn("删除计划: planId 为空");
return 0;
}
log.info("按 planId 删除计划, planId: {}", planId);
int taskRows = planTaskMapper.deleteByPlanId(planId);
int aclRows = planAccessControlMapper.deleteByPlanId(planId);
int planRows = planMapper.deleteById(planId);
return taskRows + aclRows + planRows;
}shardingsphere 都是通过代理去增强SQL,所以原始SQL看起来还是单表的操作
<delete id="deleteByPlanId">
DELETE FROM t_xdx_plan_task WHERE plan_id = #{planId}
</delete><delete id="deleteByPlanId">
DELETE FROM t_xdx_plan_access_control_list WHERE plan_id = #{planId}
</delete><delete id="deleteById">
DELETE FROM t_xdx_plan WHERE id = #{planId}
</delete>3-3-2、分析
- 数据分表是基于 created、plan_time 的,当通过planId去操作的时候,不会匹配到分表规则
- 系统配置每个表都有三个时间(2025、2026、2027),所以最终会执行9个删除SQL
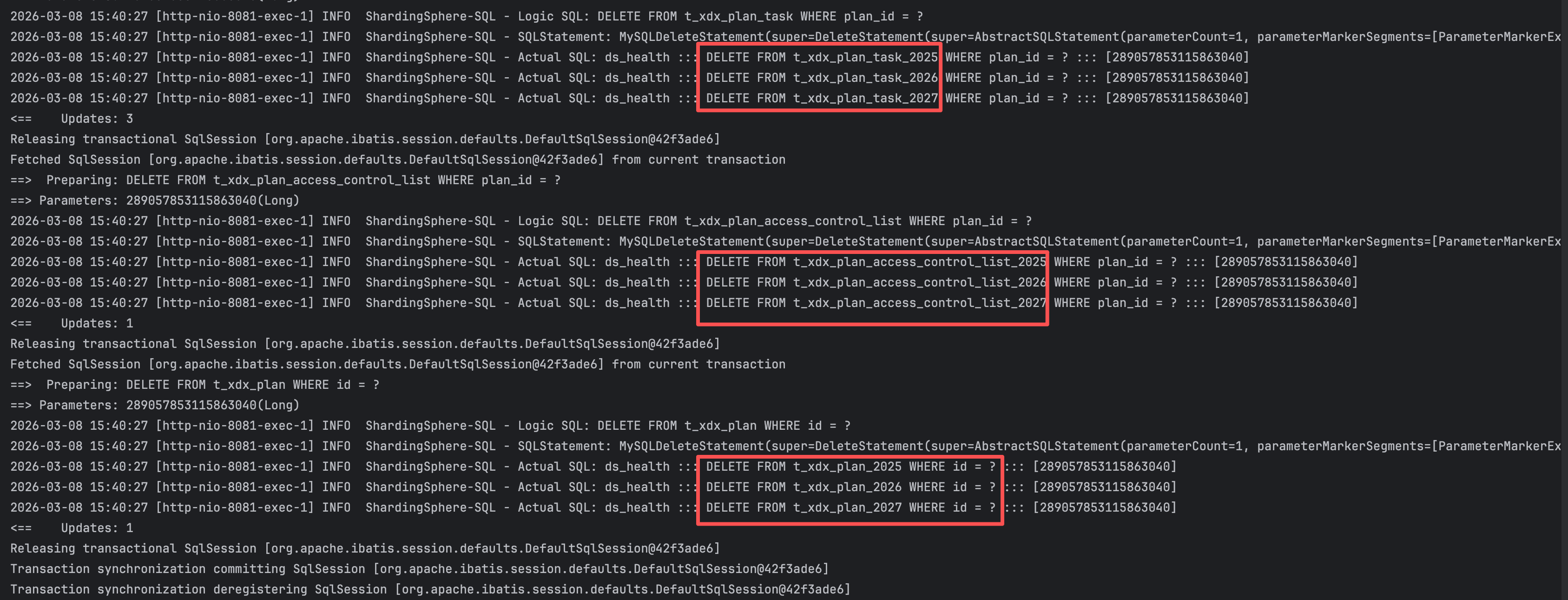
每次都操作多张表,看起来不太好,也是有办法解决的,主要思路有2个
- 带上分片策略,比如SQL改为
DELETE FROM t_xdx_plan_access_control_list WHERE plan_id = #{planId} and created = #{created} - 使用 Hint,强制指定表
// 删除时已知 created 的年份,例如 2025
try (HintManager hint = HintManager.getInstance()) {
hint.addTableShardingValue("t_xdx_plan", Year.of(2025)); // 或你算法需要的类型
planMapper.deleteById(planId);
}3-4、改
改和删类似
3-5、查 (重要)
数据如何呈现给用户,才是最重要,故而查询是最重要,也最复杂的。 来看下面这个复杂查询
<select id="listPlanTask" parameterType="com.xdx.order.params.PlanTaskQuery" resultMap="XdxPlanTaskResultMap">
SELECT
t.id,
t.plan_time,
t.plan_month,
t.status,
t.plan_id,
t.modified,
t.created,
hp.title,
hp.recurrence_flag,
hp.customer_id
FROM t_xdx_plan_task t
INNER JOIN t_xdx_plan hp ON t.plan_id = hp.id
WHERE 1 = 1
<if test="query.appUserId != null">
AND EXISTS (
SELECT 1 FROM t_xdx_plan_access_control_list acl
WHERE acl.plan_id = hp.id
AND acl.app_user_id = #{query.appUserId}
)
</if>
<if test="query.planIds != null and query.planIds.size() > 0">
AND t.plan_id IN
<foreach collection="query.planIds" item="planId" open="(" separator="," close=")">
#{planId}
</foreach>
</if>
<if test="query.planTaskIds != null and query.planTaskIds.size() > 0">
AND t.id IN
<foreach collection="query.planTaskIds" item="planTaskId" open="(" separator="," close=")">
#{planTaskId}
</foreach>
</if>
<if test="query.customerIds != null and query.customerIds.size() > 0">
AND hp.customer_id IN
<foreach collection="query.customerIds" item="customerId" open="(" separator="," close=")">
#{customerId}
</foreach>
</if>
<if test="query.months != null and query.months.size() > 0">
AND t.plan_month IN
<foreach collection="query.months" item="month" open="(" separator="," close=")">
#{month}
</foreach>
</if>
<if test="query.planStartTime != null">
AND t.plan_time >= #{query.planStartTime}
</if>
<if test="query.planEndTime != null">
AND t.plan_time <= #{query.planEndTime}
</if>
<if test="query.createdStart != null">
AND hp.created >= #{query.createdStart}
</if>
<if test="query.statuses != null and query.statuses.size() > 0">
AND t.status IN
<foreach collection="query.statuses" item="status" open="(" separator="," close=")">
#{status}
</foreach>
</if>
ORDER BY t.plan_time ASC
<if test="query.offset != null and query.pageSize != null and query.offset >= 0 and query.pageSize > 0">
LIMIT #{query.pageSize} OFFSET #{query.offset}
</if>
</select>3-5-1、不同的查询条件匹配逻辑
{
"appUserId": 1,
"pageNum": 1,
"pageSize":4
}在这个查询里面,业务查询参数只有 appUserId,它不是分表关键参数。
- t_xdx_plan_task 有 2025、2026、2027
- t_xdx_plan 和 t_xdx_plan_access_control_list 也各自有三个,但它们是一起出现的 (通过上面 application 里面的绑定关系)
所以最终的组合是 3*3 = 9,会有9次查询。 (9次查询和数据汇总SharingSphere 都会帮我们做好)
{
"appUserId": 1,
"planStartTime":"2026-01-01 12:01:01",
"pageNum": 1,
"pageSize":4
}planStartTime 是对 plan_time的匹配,AND t.plan_time >= #{query.planStartTime},这样就会过滤掉 t_xdx_plan_task_2025,最终就是 2*3 = 6
{
"appUserId": 1,
"planStartTime":"2026-01-01 12:01:01",
"planEndTime":"2026-11-01 12:01:01",
"pageNum": 1,
"pageSize":4
}planEndTime 也是对plan_time的匹配,AND t.plan_time <= #{query.planEndTime},这样就会过滤掉 t_xdx_plan_task_2027,再加上planStartTime,最终就是 1*3 = 3
{
"appUserId": 1,
"planStartTime":"2026-01-01 12:01:01",
"planEndTime":"2026-11-01 12:01:01",
"createdStart" : "2027-01-01 12:01:01",
"pageNum": 1,
"pageSize":4
}createdStart 是对created的精准匹配 ,AND hp.created >= #{query.createdStart},就只会匹配出 t_xdx_plan_2026和t_xdx_plan_access_control_list_2026,最终就是 1*1 = 1
SELECT
t.id,
t.plan_time,
t.plan_month,
t.STATUS,
t.plan_id,
t.modified,
t.created,
hp.title,
hp.recurrence_flag,
hp.customer_id
FROM
t_xdx_plan_task_2026 t
INNER JOIN t_xdx_plan_2027 hp ON t.plan_id = hp.id
WHERE
EXISTS ( SELECT 1 FROM t_xdx_plan_access_control_list_2027 acl WHERE acl.plan_id = hp.id AND acl.app_user_id = ? )
AND t.plan_time >= ?
AND t.plan_time <= ? AND hp.created >= ?
ORDER BY
t.plan_time ASC
LIMIT ? OFFSET ?业务优化:
在大多数查询的时候只有 planStartTime/planEndTime,没有 createdStart。但业务上创建一个计划的时候,子任务要么是T要么是T+1年。当有 planStartTime 的时候就可以推断出 createdStart 的范围。这样就又可以减少一次查询了
其它的字段,不是分表字段,不会影响到表的连接
3-5-2、如何查询分页
其实分页就是取总数,以及对应中间段的数量,所以我们需要一个count SQL,其它的shardingsphere都会帮我们完成
@Override
public PageResult<HealthPlanTaskVO> listPlanTask(PlanTaskQuery query) {
log.info("查询健康计划任务列表(分页), query: {}", query);
// 设置默认分页参数
if (query.getPageNum() == null || query.getPageNum() < 1) {
query.setPageNum(1);
}
if (query.getPageSize() == null || query.getPageSize() < 1) {
query.setPageSize(10);
}
// 计算偏移量
query.calculateOffset();
// 查询总数
Long total = planTaskMapper.countPlanTask(query);
// 查询列表
List<XdxPlanTask> tasks = planTaskMapper.listPlanTask(query);
// 转换为 VO
List<HealthPlanTaskVO> list = tasks.stream()
.map(this::convertToVO)
.toList();
// 返回分页结果
return PageResult.of(query.getPageNum(), query.getPageSize(), total, list);
}<!-- 统计总数查询 -->
<select id="countPlanTask" parameterType="com.xdx.order.params.PlanTaskQuery" resultType="java.lang.Long">
SELECT COUNT(*)
FROM t_xdx_plan_task t
INNER JOIN t_xdx_plan hp ON t.plan_id = hp.id
<include refid="planTaskWhereClause"/>
</select>
<!-- 核心查询:任务表 JOIN 计划表,使用逻辑表名。访问控制通过 EXISTS 过滤。 -->
<select id="listPlanTask" parameterType="com.xdx.order.params.PlanTaskQuery" resultMap="XdxPlanTaskResultMap">
SELECT
t.id,
t.plan_time,
t.plan_month,
t.status,
t.plan_id,
t.modified,
t.created,
hp.title,
hp.recurrence_flag,
hp.customer_id
FROM t_xdx_plan_task t
INNER JOIN t_xdx_plan hp ON t.plan_id = hp.id
<include refid="planTaskWhereClause"/>
ORDER BY t.plan_time ASC
<if test="query.offset != null and query.pageSize != null and query.offset >= 0 and query.pageSize > 0">
LIMIT #{query.pageSize} OFFSET #{query.offset}
</if>
</select>
<!-- 公共查询条件片段 -->
<sql id="planTaskWhereClause">
<where>
<if test="query.appUserId != null">
AND EXISTS (
SELECT 1 FROM t_xdx_plan_access_control_list acl
WHERE acl.plan_id = hp.id
AND acl.app_user_id = #{query.appUserId}
)
</if>
<if test="query.planIds != null and query.planIds.size() > 0">
AND t.plan_id IN
<foreach collection="query.planIds" item="planId" open="(" separator="," close=")">
#{planId}
</foreach>
</if>
<if test="query.planTaskIds != null and query.planTaskIds.size() > 0">
AND t.id IN
<foreach collection="query.planTaskIds" item="planTaskId" open="(" separator="," close=")">
#{planTaskId}
</foreach>
</if>
<if test="query.customerIds != null and query.customerIds.size() > 0">
AND hp.customer_id IN
<foreach collection="query.customerIds" item="customerId" open="(" separator="," close=")">
#{customerId}
</foreach>
</if>
<if test="query.months != null and query.months.size() > 0">
AND t.plan_month IN
<foreach collection="query.months" item="month" open="(" separator="," close=")">
#{month}
</foreach>
</if>
<if test="query.planStartTime != null">
AND t.plan_time >= #{query.planStartTime}
</if>
<if test="query.planEndTime != null">
AND t.plan_time <= #{query.planEndTime}
</if>
<if test="query.createdStart != null">
AND hp.created >= #{query.createdStart}
</if>
<if test="query.statuses != null and query.statuses.size() > 0">
AND t.status IN
<foreach collection="query.statuses" item="status" open="(" separator="," close=")">
#{status}
</foreach>
</if>
</where>
</sql>