【中】Dubbo自定义过滤器,过滤器源码详解(Dubbo源码四)
提示
学习完Dubbo生产者和消费者,这次来学点实用的。如果说要对Dubbo进行一些扩展,那能做的好做的也就只有在自定义过滤器这上面下功夫了
相较于消费者和生产者,Filter要简单的多。但只有知道Filter何时何地加载进去的,才算真的知道Filter的执行流程
本篇主要解决下面三个问题
- 实践生产者和消费者的自定义过滤器
- 了解什么是SPI,Dubbo的过滤器是基于SPI的
- 从源码的角度理解Filter是何时何地装载进去的
一、Filter实践
所谓的Filter就是想要在真正执行代码之前、之后做一些自己的操作,这个操作可以是任何你想的操作
定义一个Filter
import org.apache.dubbo.common.constants.CommonConstants;
import org.apache.dubbo.common.extension.Activate;
import org.apache.dubbo.rpc.*;
@Activate(group = {CommonConstants.CONSUMER,CommonConstants.PROVIDER})
public class XdxDubboFilter implements Filter {
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
System.out.println("我是Filter");
// 之前的操作
Result result = invoker.invoke(invocation);
// 之后的操作
return result;
}
}配置Filter,在 resources/META-INF/dubbo 创建一个 org.apache.dubbo.rpc.Filter 文件(就是一个文件,不需要任何格式),输入下面内容
xdxDubboFilter=com.xdx97.consumer.XdxDubboFilter文件位置,同样也是使用文档,就是这么简单,在上面的@Activate里面有个 group,可以控制这个Filter是对消费者还是生产者生效(上面配置了2个所以是生产者消费者都生效)
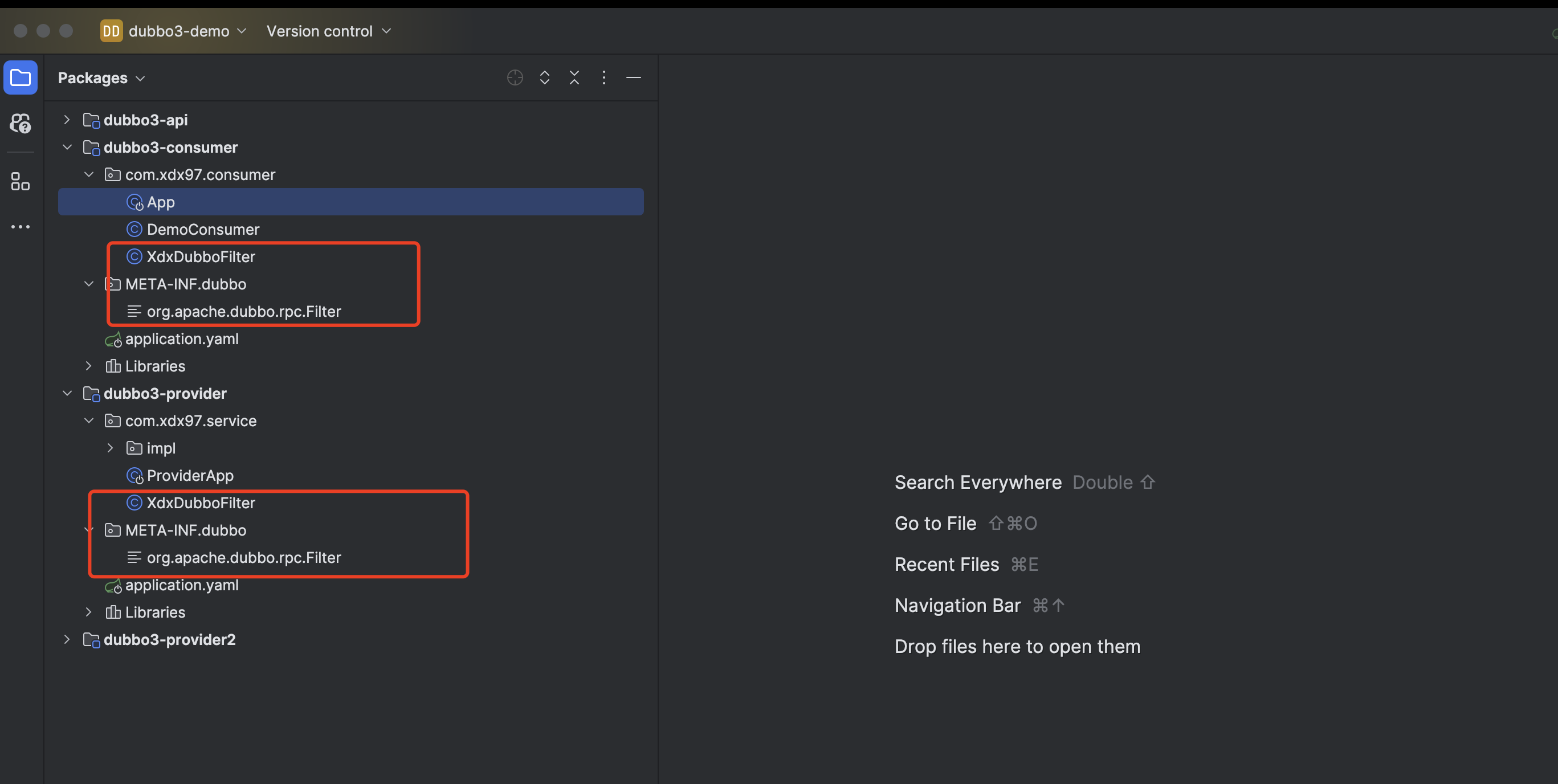
为什么要在这个目录下创建这样一个文件呢?这是Java的SPI规则
二、何为SPI
Java SPI(Service Provider Interface)
它通过定义接口、实现类、配置文件和ServiceLoader来实现模块化设计。SPI的工作流程包括定义服务接口、创建实现类、在 META-INF/services/ 目录下配置实现类的全限定名,并使用ServiceLoader动态加载这些实现。
实现一个简单的SPI
public interface SimpleService {
void execute();
}创建一个或多个实现类,例如:
public class SimpleServiceImpl implements SimpleService {
@Override
public void execute() {
System.out.println("SimpleServiceImpl executed!");
}
}在resources/META-INF/services/目录下创建一个文件,文件名是服务接口的全限定名,即:
META-INF/services/SimpleService- 文件名是 SimpleService
- 文件内容是SimpleServiceImpl
import java.util.ServiceLoader;
public class SPIDemo {
public static void main(String[] args) {
ServiceLoader<SimpleService> serviceLoader = ServiceLoader.load(SimpleService.class);
for (SimpleService service : serviceLoader) {
service.execute();
}
}
}src
└── main
├── java
│ ├── SimpleService.java
│ ├── SimpleServiceImpl.java
│ └── SPIDemo.java
└── resources
└── META-INF
└── services
└── SimpleService来看看AI对SPI优缺点的描述
1、模块化与解耦:SPI机制允许服务的实现和使用者之间完全解耦。客户端代码只依赖接口,不依赖具体实现,从而实现模块化设计。
2、动态加载与可扩展性:通过在配置文件中添加新的实现类,可以动态地扩展功能而无需修改现有代码,提升了系统的灵活性和可扩展性。
3、多实现支持:SPI允许在运行时加载多个服务实现,适用于需要支持多种实现的场景(例如JDBC、日志框架等)。
4、符合开闭原则:SPI机制符合面向对象设计中的开闭原则(对扩展开放,对修改关闭),通过新增实现类实现扩展,而不需要修改已有的代码。
1、复杂的配置管理:需要维护META-INF/services/目录下的配置文件,如果配置错误或文件名不匹配,可能导致服务加载失败或行为异常。
2、性能开销:在加载大量服务实现时,ServiceLoader会遍历所有配置文件,可能导致启动时间变长,并带来性能开销。
3、调试困难:由于SPI使用反射机制加载服务实现,调试过程中难以直接跟踪具体的实现类,增加了问题排查的难度。
4、不透明性:SPI的加载机制对于使用者来说是黑盒操作,用户通常无法直接控制具体实现的加载顺序和加载细节。
或许你会好奇不是说的 META-INF/services/, 为什么Dubbo的是 META-INF/dubbo/ 这是因为Dubbo做了扩展,请继续看下去
三、源码Filter
3-1、Filter何时应用到Dubbo的
基于之前的学习,得知不管是生产者还是消费者,在执行正式的请求或处理之前都会先经过Filter处理。而过滤器的组装都是下面这个方法
org.apache.dubbo.rpc.cluster.filter.DefaultFilterChainBuilder#buildInvokerChain
public <T> Invoker<T> buildInvokerChain(final Invoker<T> originalInvoker, String key, String group) {
// 原始的invoker
Invoker<T> last = originalInvoker;
URL url = originalInvoker.getUrl();
List<ModuleModel> moduleModels = getModuleModelsFromUrl(url);
List<Filter> filters;
// 找到符合条件的Filter
if (moduleModels != null && moduleModels.size() == 1) {
filters = ScopeModelUtil.getExtensionLoader(Filter.class, moduleModels.get(0))
.getActivateExtension(url, key, group);
} else if (moduleModels != null && moduleModels.size() > 1) {
// ...
} else {
// ...
}
// 如果过滤器存在,进行过滤器的组装,递归嵌套
if (!CollectionUtils.isEmpty(filters)) {
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new CopyOfFilterChainNode<>(originalInvoker, next, filter);
}
return new CallbackRegistrationInvoker<>(last, filters);
}
return last;
}怎么到这一步的参看
3-2、Filter 解析
从上面的SPI得知,它工作原理是读取指定目录的内容。Dubbo里面有一个类ExtensionLoader,还有一个接口LoadingStrategy。
- ExtensionLoader就是Dubbo自定义的ServiceLoader
- LoadingStrategy 定义了ExtensionLoader要加载哪些目录下的对象
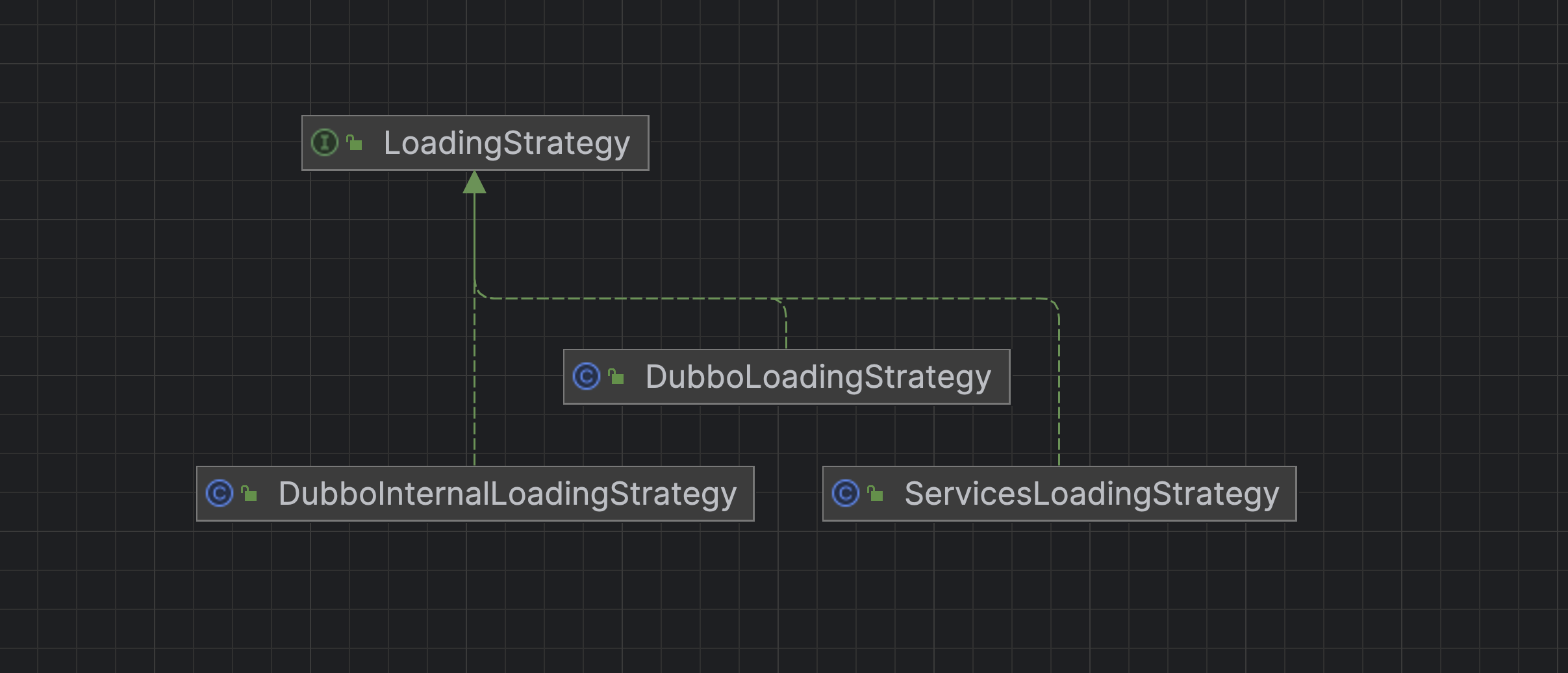
这就是为什么要把自定义过滤器放在 META-INF/dubbo/ 目录下的原因
public class DubboLoadingStrategy implements LoadingStrategy {
public DubboLoadingStrategy() {
}
public String directory() {
return "META-INF/dubbo/";
}
public boolean overridden() {
return true;
}
public int getPriority() {
return 0;
}
public String getName() {
return "DUBBO";
}
}其它的Dubbo系统Filter都可以在这个目录下找到
public class DubboInternalLoadingStrategy implements LoadingStrategy {
public DubboInternalLoadingStrategy() {
}
public String directory() {
return "META-INF/dubbo/internal/";
}
public int getPriority() {
return Integer.MIN_VALUE;
}
public String getName() {
return "DUBBO_INTERNAL";
}
}public class ServicesLoadingStrategy implements LoadingStrategy {
public ServicesLoadingStrategy() {
}
public String directory() {
return "META-INF/services/";
}
public boolean overridden() {
return true;
}
public int getPriority() {
return Integer.MAX_VALUE;
}
public String getName() {
return "SERVICES";
}
}在上面的代码中,获取ExtensionLoader,并执行的代码片段如下
filters = ScopeModelUtil.getExtensionLoader(Filter.class, moduleModels.get(0)).getActivateExtension(url, key, group);下面的代码也有点长,但不要紧,相较于生产者和消费者其实很简单了——因为它是线性的,下面就给出一些关键的流程
org.apache.dubbo.common.extension.ExtensionLoader#getActivateExtension(org.apache.dubbo.common.URL, java.lang.String[], java.lang.String)
public List<T> getActivateExtension(URL url, String[] values, String group) {
checkDestroyed();
Map<Class<?>, T> activateExtensionsMap = new TreeMap<>(activateComparator);
// ...
Set<String> namesSet = new HashSet<>(names);
if (!namesSet.contains(REMOVE_VALUE_PREFIX + DEFAULT_KEY)) {
// 双重校验防止线程冲突
if (cachedActivateGroups.size() == 0) {
synchronized (cachedActivateGroups) {
// cache all extensions
if (cachedActivateGroups.size() == 0) {
// 读取相关目录下的类,会存入 cachedActivates
getExtensionClasses();
for (Map.Entry<String, Object> entry : cachedActivates.entrySet()) {
// 循环每一个类,判断是否符合当前条件,还记得自定义过滤器上定的 group吗?在这里用上了
String name = entry.getKey();
Object activate = entry.getValue();
String[] activateGroup, activateValue;
if (activate instanceof Activate) {
activateGroup = ((Activate) activate).group();
activateValue = ((Activate) activate).value();
} else if (Dubbo2CompactUtils.isEnabled()
&& Dubbo2ActivateUtils.isActivateLoaded()
&& Dubbo2ActivateUtils.getActivateClass().isAssignableFrom(activate.getClass())) {
activateGroup = Dubbo2ActivateUtils.getGroup((Annotation) activate);
activateValue = Dubbo2ActivateUtils.getValue((Annotation) activate);
} else {
continue;
}
cachedActivateGroups.put(name, new HashSet<>(Arrays.asList(activateGroup)));
String[][] keyPairs = new String[activateValue.length][];
for (int i = 0; i < activateValue.length; i++) {
if (activateValue[i].contains(":")) {
keyPairs[i] = new String[2];
String[] arr = activateValue[i].split(":");
keyPairs[i][0] = arr[0];
keyPairs[i][1] = arr[1];
} else {
keyPairs[i] = new String[1];
keyPairs[i][0] = activateValue[i];
}
}
// 满足条件存入,下面返回
cachedActivateValues.put(name, keyPairs);
}
}
}
}
// ...
}
// ...
}