【初】Java线程池详解
我们知道频繁的创建和销毁线程是需要消耗大量的资源,所以如果我们的程序需要频繁使用多线程的话,线程池将是不二选择。
一、创建一个线程池并使用
1-1、new 的方式创建
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>());1-2、Executors 创建
ExecutorService executorService1 = Executors.newCachedThreadPool(); // SynchronousQueue
ExecutorService executorService = Executors.newFixedThreadPool(1); // LinkedBlockingQueue
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); // DelayedWorkQueue
ExecutorService executorService2 = Executors.newSingleThreadExecutor(); // LinkedBlockingQueue- newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
使用Executors创建的线程池,其实我们点进去发现底层都是 new ThreadPoolExecutor 只不过传参不一样罢了
我们可以看一下它们的关系继承图

1-3、线程池的使用
threadPoolExecutor.execute(() ->{
// 具体的业务逻辑
});- execute() 方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
- submit() 方法用于提交需要返回值的任务。线程池会返回一个 Future 类型的对象,通过这个 Future 对象可以判断任务是否执行成功
二、构造方法参数详解
2-1、corePoolSize
核心线程数,也可以理解成线程池里面大多数情况下线程的数量
2-2、maximumPoolSize
最大线程数,假如我们的核心线程数是10,最大线程数是30。
已经有10个程序在运行了,这时候还有程序需要运行,并且等待队列已经满了。相当于需要零时线程,这时候就会继续创建新的线程来执行任务。
2-3、keepAliveTime
空闲状态存活时间,如上面所说当我们线程池里面有30个线程了,这时候所有程序都执行完毕了,等待时间超过keepAliveTime的时候就会销毁线程,直到线程数小于等于核心线程数。
2-4、unit
参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性
- TimeUnit.DAYS; //天
- TimeUnit.HOURS; //小时
- TimeUnit.MINUTES; //分钟
- TimeUnit.SECONDS; //秒
- TimeUnit.MILLISECONDS; //毫秒
- TimeUnit.MICROSECONDS; //微妙
- TimeUnit.NANOSECONDS; //纳秒
2-5、workQueue
阻塞队列,当线程数超过核心程数的时候其它任务就会进入这个阻塞队列, 具体的阻塞队列下面细说
2-6、threadFactory
线程工厂,用来创建线程;
2-7、handler
拒绝策略,在使用线程池并且使用有界队列的时候,如果队列满了,任务添加到线程池的时候就会有问题,针对这些问题java线程池提供了以下几种策略
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 (默认的策略)
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
三、队列详解
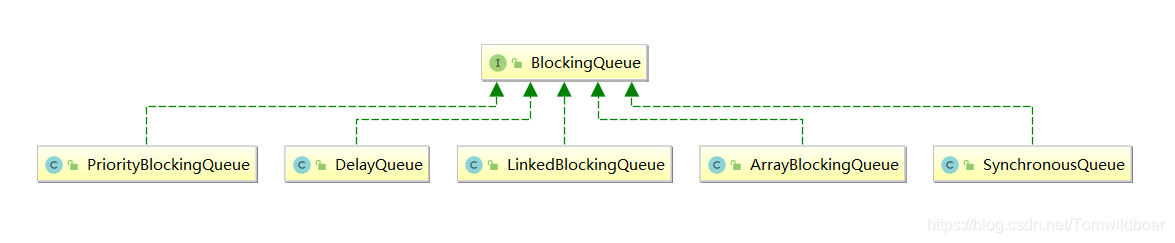
3-1、ArrayBlockingQueue
ArrayBlockingQueue底层是基于数组实现的,我们知道创建数字的时候必须指定数组的大小,同样我们创建ArrayBlockingQueue的时候也需要指定它的大小,所以它是一个有界队列。
当正在执行的线程数等于核心线程数,这时候再来的资源就会进入队列中,当队列满的时候,就会开启新的线程去执行(前提是你的最大线程数大于你的核心线程数),当达到了最大线程数的时候,如果依旧来不及消费队列就会采用拒绝策略。
3-2、LinkedBlockingQueue
LinkedBlockingQueue是基于链表实现的,链表的大小没有限制,所以它是一个无界队列,创建它的时候也可以指定队列的大小,如果不指定就是无限大(Integer.MAX_VALUE),当消费者的速度跟不上生产者速度的时候就可能产生内存溢出。
我们知道只有当队列满的时候,并且最大线程数大于核心线程数的时候才会去创建新的线程去执行。所以如果我们使用LinkedBlockingQueue的时候,没有给它设置队列大小(也就是最大值),那么这个时候的最大线程数其实是无效的。
3-3、SynchronousQueue
同步队列,是一个很特殊的队列,它没有存储资源的容器,所有的任务都是直接交给消费者的,当我们的消费者来不及消费的时候就会抛出拒绝策略,所以一般我们把最大线程数设置的很大。
它有公平模式(先进先出),和非公平模式(先进后出)可能导致一些资源永远无法执行。
3-4、PriorityBlockingQueue
PriorityBlockingQueue 无界可扩容可排序的队列
3-5、DelayQueue
DelayQueue 里面的元素必须实现Delayed接口,重写里面的getDelay、compareTo方法。
其中,compareTo 方法 getDelay 方法 就是Delayed接口的方法,我们必须实现,而且按照JAVASE文档,compareTo 方法必须提供与 getDelay 方法一致的排序,也就是说compareTo方法里可以按照getDelay方法的返回值大小排序,即在compareTo方法里比较getDelay方法返回值大小
-- https://www.cnblogs.com/myseries/p/10944211.html
DelayQueue里面的元素会按照compareTo排序好,然后按照过期时间依次去执行。